

Amazon Web Services as a Disaster Recovery Solution
By Intuitive / Dec 09,2018
What is Disaster Recovery
Disaster recovery (DR) is an area of planning that aims to protect an organization from the effects of significant negative events. DR allows an organization to maintain or quickly resume mission-critical functions following a disaster.
A disaster can be but not limited due to hardware failure,Datacenter failure or failure of service due to natural calamity etc.
To minimize the impact of a disaster, companies invest time and resources to plan and prepare, to train employees, and to document and update processes. The amount of investment for DR planning for a particular system can vary dramatically depending on the cost of a potential outage. Companies that have traditional physical environments typically must duplicate their infrastructure to ensure the availability of spare capacity in the event of a disaster. The infrastructure needs to be procured, installed, and maintained so that it is ready to support the anticipated capacity requirements. During normal operations, the infrastructure typically is under-utilized or over-provisioned.
AWS can provide a pay as you go solution for a Disaster recovery solution for on-premise infrastructure deployments.
There are two common industry standard planning metric for Disaster recovery
RTP ( Recovery Time Objective)
The time it takes after a disruption to restore a business process to its service level, as defined by the operational level agreement (OLA). For example, if a disaster occurs at 10:00 AM and the RTO is 5 hours,Then the DR process should restore the business process to the acceptable service level by 3:00 PM
RPO ( Recovery point objective)
The acceptable amount of data loss measured in time. For example, if a disaster occurs at 10:00 AM and the RPO is one hour, the system should recover all data that was in the system before 9:00 AM. Data loss will span only one hour, between 9:00 AM and 10:00 AM.
Disaster Recover Scenario Example
The following figure (Figure 1) shows a spectrum of four scenario showing how quickly the DR can be recovered ( Left to right )

Figure 1
Scenario 1: Backup and Restore
To recover your data in the event of any disaster, you must first have your data periodically backed up from your system to AWS. Backing up of data can be done through various mechanisms and your choice will be based on the RPO (Recovery Point Objective if you have a frequently changing database like say a stock market, then you will need a very high RPO. However if your data is mostly static with a low frequency of changes, you can opt for periodic incremental backup.
So to backup the data to AWS you can use Import/Export service of AWS which basically ship the media to AWS in case the data is huge and tranferring though internet is expensive and the data is mostly static with very less frequent changes. Similarly if the data is very less frequently accessed to save more cost the data can be stored in Glacier instead of S3.
The other approach to back is to use the AWS storage gateway which will create a snapshot copy of the on-premise data into AWS S3 over the internet in gateway stored volume mode or store the primary data in AWS in the gateway cache volume mode.
Once your backup mechanisms are activated you can use pre-configure AMIs . Now when a disaster strikes, EC2 (Elastic Compute Capacity) instances in the Cloud using EBS (Elastic Block Store) coupled with AMIs can access your data from the S3 (Simple Storage Service) buckets to revive your system and keep it going.
The below figure (figure 2) shows the recovery process from the backup

Figure 2
Ref: AWS Disaster Recovery White Paper
Scenario 2: Pilot Light for Quick Recovery into AWS
The term pilot light is often used to describe a DR scenario in which a minimal version of an environment is always running in the cloud.
Typically the minimal infrastructure resource is the database server that get replicated from the on-prem to AWS.This is the critical core of the infrastructure around which all the other resource will be deployed in AWS.
See the below figure (Figure 3)

Figure 3
From the network perspective we need to take care of the below points:
- Use Elastic IP addresses, which can be pre-allocated and identified in the preparation phase for DR, and associate them with your instances. Note that for MAC address-based software licensing, you can use elastic network interfaces (ENIs), which have a MAC address that can also be pre-allocated to provision licenses against. You can associate these with your instances, just as you would with Elastic IP addresses.
- Use Elastic Load Balancing (ELB) to distribute traffic to multiple instances. You would then update your DNS records to point at your Amazon EC2 instance or point to your load balancer using a CNAME. We recommend this option for traditional web-based applications.
In order to recover the system you need to provision the other application around the database using pre-define AMI’s and then change the DNS entry to point to the EC2 instances or a ELB CNAME to distribute to multiple EC2 instances.
Plz refer the figure (Figure 4 ) below

Figure 4
Scenario 3: Warm Standby Solution in AWS
In this DR scenario a scaled-down version of a fully functional environment is always running in the cloud.It further decreases the recovery time because some services are always running. By identifying your business-critical systems, you can fully duplicate these systems on AWS and have them always on.
You can put the instance behind ELB and also can use the autoscaling to support the production load in case of DR.
Since this is already up and running in a standby mode the RTO will be less in this case.
Below figure (Figure 5) shows how this is deployed
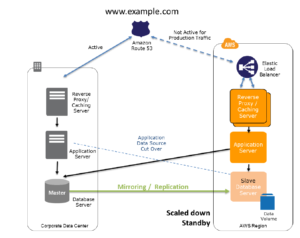
Figure 5
During the failover to DR the below changes are required
The DNS should point to AWS for traffic
Plz refer figure ( Figure 6) for more details
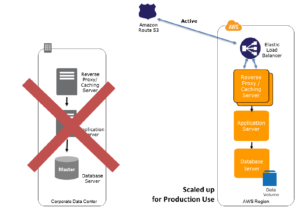
Figure 6
Scenario 4: Multi-Site Deployment
In this scenario both the on-prem and the AWS deployed side of infrastructure will process the traffic.
The database will be replicated from the production side to the DR site.
The traffic flow will be using the weighted routing policy of the Amazon Route 53 DNS to route a portion of small portion of your traffic to the AWS site during normal scenario.Please refer figure (Figure 7)

Figure 7
During the Dsaster recovery when the entire on-prem is down the instances on the AWS sitting behind the ELB will auto-scale using the AWS auto-scaling feature to handle the production Load.Th traffic will be directed to the AWS infrastructure by updating the DNS service (Route 53).
Refer figure below ( Figure 8)
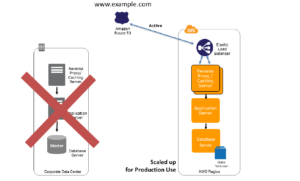
Figure 8
References:
https://aws.amazon.com/disaster-recovery/
